David Bau

I am an Assistant Professor of Computer Science at Northeastern Khoury College. My lab studies the structure and interpretation of deep networks.
We think that understanding the rich internal structure of deep networks is a grand and fundamental research question with many practical implications.
We aim to lay the groundwork for human-AI collaborative software engineering, where humans and machine-learned models both teach and learn from each other.
Want to come to Boston to work on deep learning with me? Apply to Khoury here and contact me if you are interested in joining as a graduate student or postdoc. Also check out NDIF engineering fellowships.
Publication List. (PNAS; NeurIPS; ICLR; TPAMI; CVPR; SIGGRAPH; EMNLP; ECCV; ICCV.)
Curriculum Vitae.
(PhD MIT EECS, thesis; Cornell; Harvard; Google; Microsoft. Sloan fellowship, Spira teaching award)
Publication pages on
Dblp
and Google Scholar.
 Can Rager
Can Rager
 Natalie Shapira
Natalie Shapira
 Chris Wendler
Chris Wendler
 David Atkinson
David Atkinson
 Sheridan Feucht
Sheridan Feucht
 Rohit Gandikota
Rohit Gandikota
 Arnab Sen Sharma
Arnab Sen Sharma
 Eric Todd
Eric Todd
 Koyena Pal
Koyena Pal
 Nikhil Prakash
Nikhil Prakash
 Jaden Fiotto-Kaufman
Jaden Fiotto-Kaufman
 Alex Loftus
Alex Loftus
 Grace Proebsting
Grace Proebsting
 Andy Arditi
Andy Arditi
 Jiuding Sun
Jiuding Sun
 Aaron Mueller
Aaron Mueller
 Sam Marks
Sam Marks
In the News
 Why nobody can see inside AI's black box
"People can have a variety of motivations for understanding internals...
I'm motivated by transparency because we have responsibility for the
systems we make..."
At the most fundamental level, the tech companies building these AI
systems don't fully understand how their models work internally—a
challenge inherent to the technology itself. But there's a second,
distinct barrier to transparency: Developers aren't making the data
they train these systems with available to those outside their
organizations...
Grasping the fundamental internals of AI models is important
because it could enable precise interventions when needed...
With access to AI system's training data and methods and the
computing resources needed to independently study these systems,
academic researchers could help fill this knowledge gap.
Bulletin of the Atomic Scientists by Abi Olvera, January 27, 2025.
Why nobody can see inside AI's black box
"People can have a variety of motivations for understanding internals...
I'm motivated by transparency because we have responsibility for the
systems we make..."
At the most fundamental level, the tech companies building these AI
systems don't fully understand how their models work internally—a
challenge inherent to the technology itself. But there's a second,
distinct barrier to transparency: Developers aren't making the data
they train these systems with available to those outside their
organizations...
Grasping the fundamental internals of AI models is important
because it could enable precise interventions when needed...
With access to AI system's training data and methods and the
computing resources needed to independently study these systems,
academic researchers could help fill this knowledge gap.
Bulletin of the Atomic Scientists by Abi Olvera, January 27, 2025.
 How does ChatGPT think?
"Researchers are striving to reverse-engineer artificial intelligence
and scan the 'brains' of LLMs to see what they are doing, how and why...
Researchers want explanations so that they can create safer, more
efficient and more accurate AI. Users want explanations so that they
know when to trust a chatbot's output. And regulators want explanations
so that they know what AI guard rails to put in place....
Bau and his colleagues have also developed methods
to scan and edit AI neural networks, including a technique they call
causal tracing...."
This news article in Nature surveys the emerging field of
deep network interpretation. The increasing complexity of generative
AI systems such as ChatGPT has spawned a new research subfield
that cracks open these large models and interprets their
emergent internal structure. The article surveys
perspectives on this new research area from several
relevant researchers including
David Bau,
Mor Geva,
Martin Wattenberg,
Chris Olah,
Thilo Hagendorff,
Sam Bowman,
Sandra Wachter,
Andy Zou, and
Peter Hase.
The article also highlights research from
Kenneth Li,
Jason Wei,
Miles Turpin,
Kevin Meng and
Roger Grosse.
Nature news feature by Matthew Hutson, May 14, 2024.
How does ChatGPT think?
"Researchers are striving to reverse-engineer artificial intelligence
and scan the 'brains' of LLMs to see what they are doing, how and why...
Researchers want explanations so that they can create safer, more
efficient and more accurate AI. Users want explanations so that they
know when to trust a chatbot's output. And regulators want explanations
so that they know what AI guard rails to put in place....
Bau and his colleagues have also developed methods
to scan and edit AI neural networks, including a technique they call
causal tracing...."
This news article in Nature surveys the emerging field of
deep network interpretation. The increasing complexity of generative
AI systems such as ChatGPT has spawned a new research subfield
that cracks open these large models and interprets their
emergent internal structure. The article surveys
perspectives on this new research area from several
relevant researchers including
David Bau,
Mor Geva,
Martin Wattenberg,
Chris Olah,
Thilo Hagendorff,
Sam Bowman,
Sandra Wachter,
Andy Zou, and
Peter Hase.
The article also highlights research from
Kenneth Li,
Jason Wei,
Miles Turpin,
Kevin Meng and
Roger Grosse.
Nature news feature by Matthew Hutson, May 14, 2024.
 We have launched the
National Deep Inference Fabric (NDIF)
project.
Large-scale AI presents fundamental open scientific
questions and major societal impacts that are not yet well-understood—and
they are both difficult and expensive to study. NDIF
is a major investment in scientific infrastructure to help meet
the challenge, with $9m of funding from the National Science Foundation
to develop large-scale AI inference software aimed
at enabling cutting-edge research. Questions in the public interest,
such as "how can we explain an AI decision?"
or "what can improve the safety and robustness of AI?"
The goal of NDIF is to provide a robust and transparent AI inference
service to enable scientists in every part of the country in every
field touched by AI, to expand, accelerate, and democratize impactful
AI science. (Programmers interested in the technical details can
pip install nnsight
to try NDIF today.) Users can remotely access and alter activations,
gradients, and customize any step of
large models like llama3-70b
like having a 70b model on your own laptop. This transparency
goes far behyond commercial AI inference services, and
NSF funding will expand NDIF to support every
open model and a broad range of research methods.
Read about the positions NDIF is hiring to fill on
LinkedIn,
Twitter/X, and
on the NDIF website.
NSF funds groundbreaking research led by Northeastern to democratize artificial intelligence.
Northeastern Global News, May 2, 2024.
We have launched the
National Deep Inference Fabric (NDIF)
project.
Large-scale AI presents fundamental open scientific
questions and major societal impacts that are not yet well-understood—and
they are both difficult and expensive to study. NDIF
is a major investment in scientific infrastructure to help meet
the challenge, with $9m of funding from the National Science Foundation
to develop large-scale AI inference software aimed
at enabling cutting-edge research. Questions in the public interest,
such as "how can we explain an AI decision?"
or "what can improve the safety and robustness of AI?"
The goal of NDIF is to provide a robust and transparent AI inference
service to enable scientists in every part of the country in every
field touched by AI, to expand, accelerate, and democratize impactful
AI science. (Programmers interested in the technical details can
pip install nnsight
to try NDIF today.) Users can remotely access and alter activations,
gradients, and customize any step of
large models like llama3-70b
like having a 70b model on your own laptop. This transparency
goes far behyond commercial AI inference services, and
NSF funding will expand NDIF to support every
open model and a broad range of research methods.
Read about the positions NDIF is hiring to fill on
LinkedIn,
Twitter/X, and
on the NDIF website.
NSF funds groundbreaking research led by Northeastern to democratize artificial intelligence.
Northeastern Global News, May 2, 2024.
Selected Projects
 Concept Sliders.
While GANs are famous for containing disenangled latents that can control a variety
of interpretable image attributes, it has not been known whether similar controllable
latents are present in diffusion models.
In this work, we develop Concept Sliders, a way of finding
LoRA adjustments to diffusion model weights that cleanly and smoothly
control a single disentangled concept. With Concept Sliders, an
artist can easily modulate a single attribute like "age" or
"smiling" or even "cooked food" to smoothly adjust the visual
characteristics of an image.
Concept sliders are based on the guided-training technique underling
our previous ESD work, but
instead of erasing a concept, we develop the needed techniques to
modulate or amplify a concept without changing the underlying layout
of the image, and without entangling the concept with correlated
concepts that we wish to remain unchanged. Concept sliders have been
an open-source hit among the artistic community, and they also provide
a promising window into the organization of visual concept information
within the parameter space of diffusion models. The paper develops
and evaluates over 50 different concept sliders including very interesting
sliders that reduce visible distortions in diffusion model output, and
examines their efficacy, specificity, and composability.
R Gandikota, J Materzyńska, T Zhou, A Torralba,
D Bau.
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
Concept Sliders.
While GANs are famous for containing disenangled latents that can control a variety
of interpretable image attributes, it has not been known whether similar controllable
latents are present in diffusion models.
In this work, we develop Concept Sliders, a way of finding
LoRA adjustments to diffusion model weights that cleanly and smoothly
control a single disentangled concept. With Concept Sliders, an
artist can easily modulate a single attribute like "age" or
"smiling" or even "cooked food" to smoothly adjust the visual
characteristics of an image.
Concept sliders are based on the guided-training technique underling
our previous ESD work, but
instead of erasing a concept, we develop the needed techniques to
modulate or amplify a concept without changing the underlying layout
of the image, and without entangling the concept with correlated
concepts that we wish to remain unchanged. Concept sliders have been
an open-source hit among the artistic community, and they also provide
a promising window into the organization of visual concept information
within the parameter space of diffusion models. The paper develops
and evaluates over 50 different concept sliders including very interesting
sliders that reduce visible distortions in diffusion model output, and
examines their efficacy, specificity, and composability.
R Gandikota, J Materzyńska, T Zhou, A Torralba,
D Bau.
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
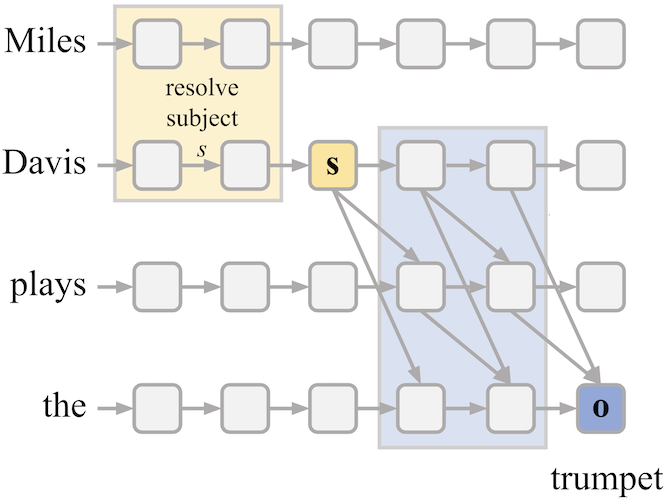 Linearity of Relation Decoding in Transformer LMs.
What is the right level of abstraction to use when understanding a huge network?
While it is natural to examine individual neurons, attention heads, modules, and
representation vectors, we should also ask whether taking a holistic view of
a larger part of the network can reveal any higher-level structure. In this work,
we ask how relationships between entities and their attributes are represented,
and we measure the power of the Jacobian—the matrix derivative—to
capture the action of a range of transformer layers in applying a relation to an entity.
When a representation vector passes through a range of transformer layers, it
is subjected to a very nonlinear transformation. Yet in this paper we find that
when the network resolves a specific relationship such as
person X plays instrument Y, the action of the transformer from the vector
for X to the vector for Y will often be essentially linear, suggesting
that the information about Y is already present in X. Moreover the linear operator
can be extracted by examining the Jacobian using as few as a single example of
the relation. We analyze more than 40 different relations to determine which
have a linear representation, and we introduce a tool, the attribute lens
that exploits linearity to visualize the relational information carried in a
state vector.
E Hernandez, A Sen Sharma, T Haklay, K Meng, M Wattenberg, J Andreas, Y Belinkov,
D Bau.
Linearity of Relation Decoding in Transformer Language Models.
Linearity of Relation Decoding in Transformer LMs.
What is the right level of abstraction to use when understanding a huge network?
While it is natural to examine individual neurons, attention heads, modules, and
representation vectors, we should also ask whether taking a holistic view of
a larger part of the network can reveal any higher-level structure. In this work,
we ask how relationships between entities and their attributes are represented,
and we measure the power of the Jacobian—the matrix derivative—to
capture the action of a range of transformer layers in applying a relation to an entity.
When a representation vector passes through a range of transformer layers, it
is subjected to a very nonlinear transformation. Yet in this paper we find that
when the network resolves a specific relationship such as
person X plays instrument Y, the action of the transformer from the vector
for X to the vector for Y will often be essentially linear, suggesting
that the information about Y is already present in X. Moreover the linear operator
can be extracted by examining the Jacobian using as few as a single example of
the relation. We analyze more than 40 different relations to determine which
have a linear representation, and we introduce a tool, the attribute lens
that exploits linearity to visualize the relational information carried in a
state vector.
E Hernandez, A Sen Sharma, T Haklay, K Meng, M Wattenberg, J Andreas, Y Belinkov,
D Bau.
Linearity of Relation Decoding in Transformer Language Models.
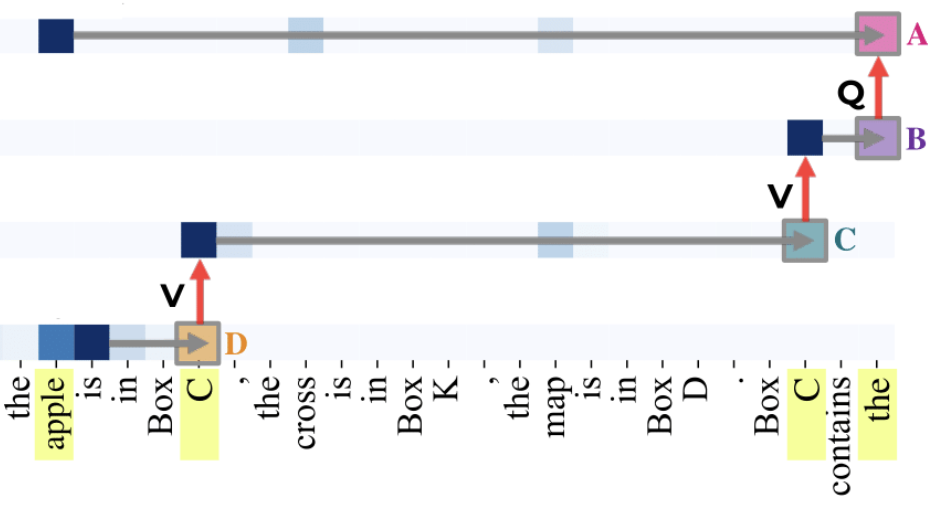 Fine-Tuning Enhances Existing Mechanisms.
When you fine-tune an LLM, are you teaching it something new or
exposing what it already knows? In this work, we pin down the detailed
structure of the mechanisms for an entity-tracking task using new
patching techniques, revealing a pre-existing circuit when a
capability emerges from fine-tuning.
The paper applies path-patching causal mediation methods as
used in Wang 2022 (IOI)
to identify the components for a circuit for entity
tracking that emerges after fine-tuning. Interestingly, we find that
the components already existed in the model prior to fine-tuning.
Furthermore we use
our DCM patching method
to deduce the type of information being transmitted at
most of the steps before and after fine-tuning, and find that
the role of the information is unchanged under fine-tuning.
Finally, we introduce Cross-Model Activation Patching (CMAP) to
test whether the encoding of information is changed after fine-tuning,
and we find that the encodings are compatible, not only allowing
interchange, but also revealing that improved task performance
can be obtained by directly patching model activations between models.
N Prakash, T R Shaham, T Haklay, Y Belinkov, D Bau.
Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking.
Fine-Tuning Enhances Existing Mechanisms.
When you fine-tune an LLM, are you teaching it something new or
exposing what it already knows? In this work, we pin down the detailed
structure of the mechanisms for an entity-tracking task using new
patching techniques, revealing a pre-existing circuit when a
capability emerges from fine-tuning.
The paper applies path-patching causal mediation methods as
used in Wang 2022 (IOI)
to identify the components for a circuit for entity
tracking that emerges after fine-tuning. Interestingly, we find that
the components already existed in the model prior to fine-tuning.
Furthermore we use
our DCM patching method
to deduce the type of information being transmitted at
most of the steps before and after fine-tuning, and find that
the role of the information is unchanged under fine-tuning.
Finally, we introduce Cross-Model Activation Patching (CMAP) to
test whether the encoding of information is changed after fine-tuning,
and we find that the encodings are compatible, not only allowing
interchange, but also revealing that improved task performance
can be obtained by directly patching model activations between models.
N Prakash, T R Shaham, T Haklay, Y Belinkov, D Bau.
Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking.
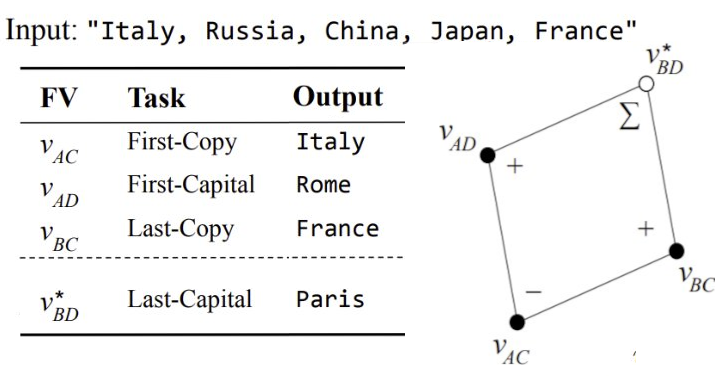 Function Vectors in Large Language Models.
The idea of treating a function reference as data is one of the most powerful
concepts in computer science, enabling complex computational forms.
Do neural networks learn to represent functions as data?
In this paper, we study in-context-learning inside large transformer
language models and show evidence that vector representations of
functions appear.
Function vectors (FVs) emerge when a language model generalizes
a list of demonstrations of input-output pairs (via in-context
learning, ICL). To study how ICL works, we apply
causal mediation analysis to identify attention heads
that transport information that determines the task to execute.
This analysis reveals a small number of attention heads that transport
a vector which we call a function vector (FV), that
generically encodes the task. We study the properties of FVs,
finding that they can trigger execution of the function when
injected into very different contexts including natural text.
We find that FVs seem to directly encode the word embeddings
of the output space, and that they also trigger nontrivial
transformer calculations that differ from word-vector arithmetic.
FVs are able to obey semantic vector algebra, but rather than
operating on word embeddings, they enable compositions of
function execution.
E Todd, M L Li, A Sen Sharma, A Mueller, B C Wallace, D Bau.
Function Vectors in Large Language Models.
Function Vectors in Large Language Models.
The idea of treating a function reference as data is one of the most powerful
concepts in computer science, enabling complex computational forms.
Do neural networks learn to represent functions as data?
In this paper, we study in-context-learning inside large transformer
language models and show evidence that vector representations of
functions appear.
Function vectors (FVs) emerge when a language model generalizes
a list of demonstrations of input-output pairs (via in-context
learning, ICL). To study how ICL works, we apply
causal mediation analysis to identify attention heads
that transport information that determines the task to execute.
This analysis reveals a small number of attention heads that transport
a vector which we call a function vector (FV), that
generically encodes the task. We study the properties of FVs,
finding that they can trigger execution of the function when
injected into very different contexts including natural text.
We find that FVs seem to directly encode the word embeddings
of the output space, and that they also trigger nontrivial
transformer calculations that differ from word-vector arithmetic.
FVs are able to obey semantic vector algebra, but rather than
operating on word embeddings, they enable compositions of
function execution.
E Todd, M L Li, A Sen Sharma, A Mueller, B C Wallace, D Bau.
Function Vectors in Large Language Models.
 Unified Concept Editing in Diffusion Models.
Text-to-image diffusion models such as Stable Diffusion have many issues
that limit their suitability for real-world deployment: they amplify racial and
gender biases; they imitate copyrighted images; and they generate offensive content.
We introduce a method, Unified Concept Editing, that allows precise editing of many
concepts within a diffusion model, and we show that it can be used to reduce bias,
copyright, and offensive content issues simultaneously.
Our UCE method is a generalization and improvement upon the
ROME,
MEMIT, and
TIME methods. It
modifies the associations between textual concepts and visual concepts by
directly editing the cross-attention parameters in the diffusion model
without any additional training images. Its closed-form parameter modification
explicitly applies an optimal change to sets of concepts while protecting
other sets of concepts from unintended modification. The paper compares UCE
to previous state-of-the-art erasure, debiasing, and offensive image removal
methods and shows that our unified editing method outperforms previous separate
approaches by a significant margin.
R Gandikota, H Orad, Y Belinkov, J Materzyńska, D Bau.
Unified Concept Editing in Diffusion Models. WACV 2024.
Unified Concept Editing in Diffusion Models.
Text-to-image diffusion models such as Stable Diffusion have many issues
that limit their suitability for real-world deployment: they amplify racial and
gender biases; they imitate copyrighted images; and they generate offensive content.
We introduce a method, Unified Concept Editing, that allows precise editing of many
concepts within a diffusion model, and we show that it can be used to reduce bias,
copyright, and offensive content issues simultaneously.
Our UCE method is a generalization and improvement upon the
ROME,
MEMIT, and
TIME methods. It
modifies the associations between textual concepts and visual concepts by
directly editing the cross-attention parameters in the diffusion model
without any additional training images. Its closed-form parameter modification
explicitly applies an optimal change to sets of concepts while protecting
other sets of concepts from unintended modification. The paper compares UCE
to previous state-of-the-art erasure, debiasing, and offensive image removal
methods and shows that our unified editing method outperforms previous separate
approaches by a significant margin.
R Gandikota, H Orad, Y Belinkov, J Materzyńska, D Bau.
Unified Concept Editing in Diffusion Models. WACV 2024.
 Future Lens.
Autoregressive language models like GPT are trained to
predict the next word. But we found they are also often thinking
several further tokens ahead! In this work, we measure this
future information, and we show how to extend the
logit lens
to reveal a run of future anticipated tokens from individual transformer
hidden states.
Our paper experiments with several ways to decode future tokens from a
single hidden state. Inspired by "tuned lens" methods from
Belrose and
Yom Din that
skip to future layers, we first try training a simple
linear readout model. We also try transplanting the hidden state
into the context of a prompt specially chosen to evoke future output.
Using a tuned prompt
reveals that two-ahead tokens can be predicted with more than 48% accuracy,
which is good enough to be useful for "future lens" visualizations.
K Pal, J Sun, A Yuan, B C Wallace, D Bau.
Future Lens: Anticipating Subsequent Tokens from a Single Hidden State.
CoNLL 2023.
Future Lens.
Autoregressive language models like GPT are trained to
predict the next word. But we found they are also often thinking
several further tokens ahead! In this work, we measure this
future information, and we show how to extend the
logit lens
to reveal a run of future anticipated tokens from individual transformer
hidden states.
Our paper experiments with several ways to decode future tokens from a
single hidden state. Inspired by "tuned lens" methods from
Belrose and
Yom Din that
skip to future layers, we first try training a simple
linear readout model. We also try transplanting the hidden state
into the context of a prompt specially chosen to evoke future output.
Using a tuned prompt
reveals that two-ahead tokens can be predicted with more than 48% accuracy,
which is good enough to be useful for "future lens" visualizations.
K Pal, J Sun, A Yuan, B C Wallace, D Bau.
Future Lens: Anticipating Subsequent Tokens from a Single Hidden State.
CoNLL 2023.
 Erasing Concepts from Diffusion Models.
We propose a method for fine-tuning model weights to erase concepts from
diffusion models using their own knowledge. Given just the text of the concept
to be erased, our method can edit the model weights to erase the concept while
minimizing the inteference with other concepts. This type of fine-tuning has
an advantage over previous methods: it is not easy to circumvent because it
modifies weights, yet it is fast and practical because it avoids the expense
of retraining the whole model on filtered training data.
The ESD method erases a concept by using the original model's own
knowledge of the concept as a guide while training a modified model.
Rather than guiding the new model to imitate the original exactly, the new model
is guided to imitate the original, while reversing its behavior of the selected
concept.
This objective corresponds to an exact ratio of probability distributions,
and is straightforward to compute, equivalent to an application of
classifier-free guidance
for training rather than inference. Our paper studies the ESD method
as used to tune different sets of parameters, and as
applied to a variety of concept-erasure applications including artistic style
removal, offensive-image removal, and removing knowledge of object classes.
R Gandikota, J Materzyńska, Jaden Fiotto-Kaufman, D Bau.
Erasing Concepts from Diffusion Models. ICCV 2023.
Erasing Concepts from Diffusion Models.
We propose a method for fine-tuning model weights to erase concepts from
diffusion models using their own knowledge. Given just the text of the concept
to be erased, our method can edit the model weights to erase the concept while
minimizing the inteference with other concepts. This type of fine-tuning has
an advantage over previous methods: it is not easy to circumvent because it
modifies weights, yet it is fast and practical because it avoids the expense
of retraining the whole model on filtered training data.
The ESD method erases a concept by using the original model's own
knowledge of the concept as a guide while training a modified model.
Rather than guiding the new model to imitate the original exactly, the new model
is guided to imitate the original, while reversing its behavior of the selected
concept.
This objective corresponds to an exact ratio of probability distributions,
and is straightforward to compute, equivalent to an application of
classifier-free guidance
for training rather than inference. Our paper studies the ESD method
as used to tune different sets of parameters, and as
applied to a variety of concept-erasure applications including artistic style
removal, offensive-image removal, and removing knowledge of object classes.
R Gandikota, J Materzyńska, Jaden Fiotto-Kaufman, D Bau.
Erasing Concepts from Diffusion Models. ICCV 2023.
 Locating and Editing Factual Associations in GPT.
In this project, we show that factual knowledge within GPT also corresponds to
a localized computation that can be directly edited. For example, we can make a
small change to a small set of the weights of GPT-J to teach it the counterfactual
"Eiffel Tower is located in the city of Rome." Rather than merely regurgitating the new
sentance, it will generalize that specific counterfactual knowledge and apply it in
very different linguistic contexts.
To show that factual knowledge within a GPT model corresponds to a simple, localized,
and directly editable computation, we introduce three new concepts.
(1) We introduce Causal Tracing, a method to locate decisive information within
a network by corrupting and restoring hidden neural states; traces reveal how
information about a fact is retrieved by MLP layers in the network.
(2) We show how to apply rank-one matrix edits (ROME) to
change individual memories within an MLP module within a transformer.
(3) And we show how to distinguish between generalized factual knowledge and rote
regurgitation of a fact, using a new data set called CounterFact.
K Meng* and D Bau*, A Andonian, Y Belinkov.
Locating and Editing Factual Associations in GPT.
NeurIPS 2022.
Locating and Editing Factual Associations in GPT.
In this project, we show that factual knowledge within GPT also corresponds to
a localized computation that can be directly edited. For example, we can make a
small change to a small set of the weights of GPT-J to teach it the counterfactual
"Eiffel Tower is located in the city of Rome." Rather than merely regurgitating the new
sentance, it will generalize that specific counterfactual knowledge and apply it in
very different linguistic contexts.
To show that factual knowledge within a GPT model corresponds to a simple, localized,
and directly editable computation, we introduce three new concepts.
(1) We introduce Causal Tracing, a method to locate decisive information within
a network by corrupting and restoring hidden neural states; traces reveal how
information about a fact is retrieved by MLP layers in the network.
(2) We show how to apply rank-one matrix edits (ROME) to
change individual memories within an MLP module within a transformer.
(3) And we show how to distinguish between generalized factual knowledge and rote
regurgitation of a fact, using a new data set called CounterFact.
K Meng* and D Bau*, A Andonian, Y Belinkov.
Locating and Editing Factual Associations in GPT.
NeurIPS 2022.
 Rewriting a Deep Generative Model.
Deep network training is a blind optimization procedure
where programmers define objectives but not the solutions that emerge.
In this paper we ask if deep networks can be created in different way:
we ask if a user can directly rewrite the rules of a model.
We develop a method and a
user interface that allows simple visual editing of the rules of
a GAN, and demonstrate direct editing of high-level rules in pretrained
state-of-the-art StyleGANv2 models. Our method finds connections
between modern large network layers and the classic neural data structure
of Optimal Linear Associative Memory, and shows that it is feasible
for a person to directly edit the weights of a large model to change
its behavior, without training againist a data set, by understanding
the model's internal structure.
D Bau, S Liu, TZ Wang, JY Zhu, A Torralba.
Rewriting a Deep Generative Model.
ECCV 2020 oral.
Rewriting a Deep Generative Model.
Deep network training is a blind optimization procedure
where programmers define objectives but not the solutions that emerge.
In this paper we ask if deep networks can be created in different way:
we ask if a user can directly rewrite the rules of a model.
We develop a method and a
user interface that allows simple visual editing of the rules of
a GAN, and demonstrate direct editing of high-level rules in pretrained
state-of-the-art StyleGANv2 models. Our method finds connections
between modern large network layers and the classic neural data structure
of Optimal Linear Associative Memory, and shows that it is feasible
for a person to directly edit the weights of a large model to change
its behavior, without training againist a data set, by understanding
the model's internal structure.
D Bau, S Liu, TZ Wang, JY Zhu, A Torralba.
Rewriting a Deep Generative Model.
ECCV 2020 oral.
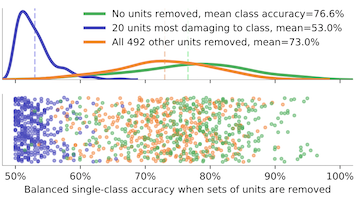 Understanding the Role of Individual Units in a Deep Neural Network.
The causal role of individual units within a deep network can be
measured by directly changing those units and observing the impact.
In this study, we unify and extend the netdissect and gandissect methods
to compare and understand classifiers and generators. Removing sets of
units from a classifier reveals a sparse computational structure:
we find that a small set of neurons is important
for the accuracy of an individual classifier output class, and
that neurons that are important for more classes also are more
human-interpretable.
D Bau, JY Zhu, H Strobelt, A Lapedriza,
B Zhou, A Torralba. Understanding the Role of Individual Units in
a Deep Neural Network.
Proceedings of the National Academy of Sciences. 2020.
Understanding the Role of Individual Units in a Deep Neural Network.
The causal role of individual units within a deep network can be
measured by directly changing those units and observing the impact.
In this study, we unify and extend the netdissect and gandissect methods
to compare and understand classifiers and generators. Removing sets of
units from a classifier reveals a sparse computational structure:
we find that a small set of neurons is important
for the accuracy of an individual classifier output class, and
that neurons that are important for more classes also are more
human-interpretable.
D Bau, JY Zhu, H Strobelt, A Lapedriza,
B Zhou, A Torralba. Understanding the Role of Individual Units in
a Deep Neural Network.
Proceedings of the National Academy of Sciences. 2020.
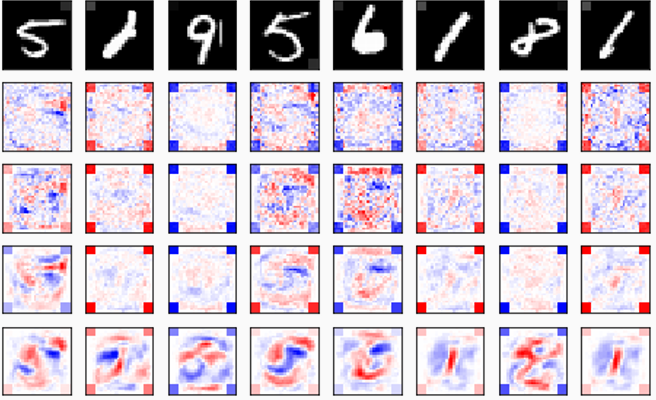 Structure and Interpretation of Deep Networks.
Most introductory courses on deep networks focus on how to train models, but it
is just as important to understand the structure and behavior of the models
after training is done. By bringing current research in deep network
interpretation
to students, the SIDN course is designed to start filling that gap.
Organized with Yonatan Belinkov,
Julius Adebayo
and a group of a dozen brilliant speakers,
our course covered salience methods, global model analysis,
adversarial robustness, fairness, interactive methods, and natural
language explanations. Each topic is anchored by a set of
hands-on exercises in Colab notebooks that are posted
online for students to work through and explore.
Organizers D Bau,
Y Belinkov, J Adebayo, H Strobelt, A Ross, V Petsiuk, S Gehrmann, M Suzgun,
S Santurkar, D Tsipras, I Chen, J Mu, J Andreas.
Structure and Interpretation of Deep Networks.
2020 IAP Course at MIT.
Structure and Interpretation of Deep Networks.
Most introductory courses on deep networks focus on how to train models, but it
is just as important to understand the structure and behavior of the models
after training is done. By bringing current research in deep network
interpretation
to students, the SIDN course is designed to start filling that gap.
Organized with Yonatan Belinkov,
Julius Adebayo
and a group of a dozen brilliant speakers,
our course covered salience methods, global model analysis,
adversarial robustness, fairness, interactive methods, and natural
language explanations. Each topic is anchored by a set of
hands-on exercises in Colab notebooks that are posted
online for students to work through and explore.
Organizers D Bau,
Y Belinkov, J Adebayo, H Strobelt, A Ross, V Petsiuk, S Gehrmann, M Suzgun,
S Santurkar, D Tsipras, I Chen, J Mu, J Andreas.
Structure and Interpretation of Deep Networks.
2020 IAP Course at MIT.
 Seeing what a GAN Cannot Generate
studies mode dropping by asking the inverse question:
how can we decompose and understand what a GAN cannot do?
A core challenge faced by GANs is mode dropping
or mode collapse, which is the tendendency for a GAN generator to
focus on a few modes and omit other parts of the distribution.
State-of-the-art GANs apply training methods designed to reduce
mode collapse, but analyzing the phenomenon remains difficult for large
distributions: examination of output samples reveals what a GAN can
do, not what it cannot do. So in this paper we
develop a pair of complementary methods for decomposing what GAN omits,
looking at segmentation statistics over a distribution, and also visualizing
omissions in specific instances by calculating inversions of a GAN generator.
Surprisingly, we find that a state-of-the-art GAN will sometimes cleanly
omit whole classes of objects from its output, hiding these omissions
by creating realistic instances without those objects.
D Bau, JY Zhu, J Wulff, W Peebles, H Strobelt,
B Zhou, A Torralba. Seeing What a GAN Cannot Generate.
ICCV 2019 oral.
Seeing what a GAN Cannot Generate
studies mode dropping by asking the inverse question:
how can we decompose and understand what a GAN cannot do?
A core challenge faced by GANs is mode dropping
or mode collapse, which is the tendendency for a GAN generator to
focus on a few modes and omit other parts of the distribution.
State-of-the-art GANs apply training methods designed to reduce
mode collapse, but analyzing the phenomenon remains difficult for large
distributions: examination of output samples reveals what a GAN can
do, not what it cannot do. So in this paper we
develop a pair of complementary methods for decomposing what GAN omits,
looking at segmentation statistics over a distribution, and also visualizing
omissions in specific instances by calculating inversions of a GAN generator.
Surprisingly, we find that a state-of-the-art GAN will sometimes cleanly
omit whole classes of objects from its output, hiding these omissions
by creating realistic instances without those objects.
D Bau, JY Zhu, J Wulff, W Peebles, H Strobelt,
B Zhou, A Torralba. Seeing What a GAN Cannot Generate.
ICCV 2019 oral.
 GAN Paint
applies
GAN dissection to the manipulation of user-provided real
photographs. By encoding a scene into a representation that can
be rendered by a generator network derived from a GAN, a user
can manipulate photo semantics, painting objects such as doors,
windows, trees,
and domes. The details of rendering objects in plausible
configurations is left to the network.
Our previous GAN dissection work showed how to manipulate random
synthetic images generated by an unconditional GAN. To manipulate
a real photograph X instead,
the generator must be guided to reproduce the photograph faithfully.
While previous work
has investigated finding the best input z
so that G(z)≈X, we show that it is useful to also optimize
the parameters of G itself. Even in cases where the GAN is not
capable of rendering the details of the user-provided photo, a nearby
GAN generator can be found that does. We
implemented our algorithm using an interactive painting app at
ganpaint.io.
D Bau, H Strobelt, W Peebles, J Wulff, B Zhou,
JY Zhu, A Torralba. Semantic Photo Manipulation
with a Generative Image Prior.
In SIGGRAPH 2019.
GAN Paint
applies
GAN dissection to the manipulation of user-provided real
photographs. By encoding a scene into a representation that can
be rendered by a generator network derived from a GAN, a user
can manipulate photo semantics, painting objects such as doors,
windows, trees,
and domes. The details of rendering objects in plausible
configurations is left to the network.
Our previous GAN dissection work showed how to manipulate random
synthetic images generated by an unconditional GAN. To manipulate
a real photograph X instead,
the generator must be guided to reproduce the photograph faithfully.
While previous work
has investigated finding the best input z
so that G(z)≈X, we show that it is useful to also optimize
the parameters of G itself. Even in cases where the GAN is not
capable of rendering the details of the user-provided photo, a nearby
GAN generator can be found that does. We
implemented our algorithm using an interactive painting app at
ganpaint.io.
D Bau, H Strobelt, W Peebles, J Wulff, B Zhou,
JY Zhu, A Torralba. Semantic Photo Manipulation
with a Generative Image Prior.
In SIGGRAPH 2019.
 GAN Dissection
investigates the internals of a GAN, and shows how neurons can be
directly manipulated
to change the behavior of a generator.
Here we ask whether the apparent
structure that we found in classifiers also appears in a setting with
no supervision from labels. Strikingly, we find that a state-of-the-art
GAN trained to generate complex scenes will learn neurons that are
specific to types of objects in the scene, such as neurons for trees,
doors, windows, and rooftops.
The work shows how to find such neurons, and shows that by forcing
the neurons on and off, you can cause a generator to draw or remove
specific types of objects in a scene.
D Bau, JY Zhu, H Strobelt, B Zhou, JB Tenenbaum,
WT Freeman, A Torralba. GAN Dissection:
Visualizing and Understanding Generative Adversarial Networks.
In ICLR 2019.
GAN Dissection
investigates the internals of a GAN, and shows how neurons can be
directly manipulated
to change the behavior of a generator.
Here we ask whether the apparent
structure that we found in classifiers also appears in a setting with
no supervision from labels. Strikingly, we find that a state-of-the-art
GAN trained to generate complex scenes will learn neurons that are
specific to types of objects in the scene, such as neurons for trees,
doors, windows, and rooftops.
The work shows how to find such neurons, and shows that by forcing
the neurons on and off, you can cause a generator to draw or remove
specific types of objects in a scene.
D Bau, JY Zhu, H Strobelt, B Zhou, JB Tenenbaum,
WT Freeman, A Torralba. GAN Dissection:
Visualizing and Understanding Generative Adversarial Networks.
In ICLR 2019.
 Network Dissection
is a technique for quantifying and automatically
estimating the human interpretability (and interpretation) of units
within any deep neural network for vision.
Building upon a surprising
2014 finding by Bolei Zhou,
network dissection defines a dictionary of 1197 human-labeled
visual concepts, each represented as a segmentation problem, then
it estimates interpretability by evaluating each hidden convolutional
unit as a solution to those problems.
I have used network dissection to reveal that representation space is
not isotropic: learned representations have an unusually high agreement
with human-labeled concepts that vanishes under a change in basis.
We gave an oral presentation about
the technique and the insights it provides at CVPR 2017.
D Bau, B Zhou, A Khosla, A Oliva, and A Torralba. Network Dissection:
Quantifying the Intepretability of Deep Visual Representations.
CVPR 2017 oral.
Network Dissection
is a technique for quantifying and automatically
estimating the human interpretability (and interpretation) of units
within any deep neural network for vision.
Building upon a surprising
2014 finding by Bolei Zhou,
network dissection defines a dictionary of 1197 human-labeled
visual concepts, each represented as a segmentation problem, then
it estimates interpretability by evaluating each hidden convolutional
unit as a solution to those problems.
I have used network dissection to reveal that representation space is
not isotropic: learned representations have an unusually high agreement
with human-labeled concepts that vanishes under a change in basis.
We gave an oral presentation about
the technique and the insights it provides at CVPR 2017.
D Bau, B Zhou, A Khosla, A Oliva, and A Torralba. Network Dissection:
Quantifying the Intepretability of Deep Visual Representations.
CVPR 2017 oral.
 Blocks and Beyond
is a workshop I helped organize to bring together researchers who are
investigating blocked-based interfaces to simplify programming for
novices and casual programmers.
The workshop was oversubscribed, and the presented
work was interesting both for its breadth and depth. Afterwards, we
wrote a review paper to survey the history, foundations, and
state-of-the-art in the field.
The review appears in the June 2017 Communications of the ACM; also see the video overview.
D Bau, J Gray, C Kelleher, J Sheldon, F Turbak. Learnable Programming: Blocks and Beyond. Communications of the ACM, pp. 72-80. June 2017.
Blocks and Beyond
is a workshop I helped organize to bring together researchers who are
investigating blocked-based interfaces to simplify programming for
novices and casual programmers.
The workshop was oversubscribed, and the presented
work was interesting both for its breadth and depth. Afterwards, we
wrote a review paper to survey the history, foundations, and
state-of-the-art in the field.
The review appears in the June 2017 Communications of the ACM; also see the video overview.
D Bau, J Gray, C Kelleher, J Sheldon, F Turbak. Learnable Programming: Blocks and Beyond. Communications of the ACM, pp. 72-80. June 2017.
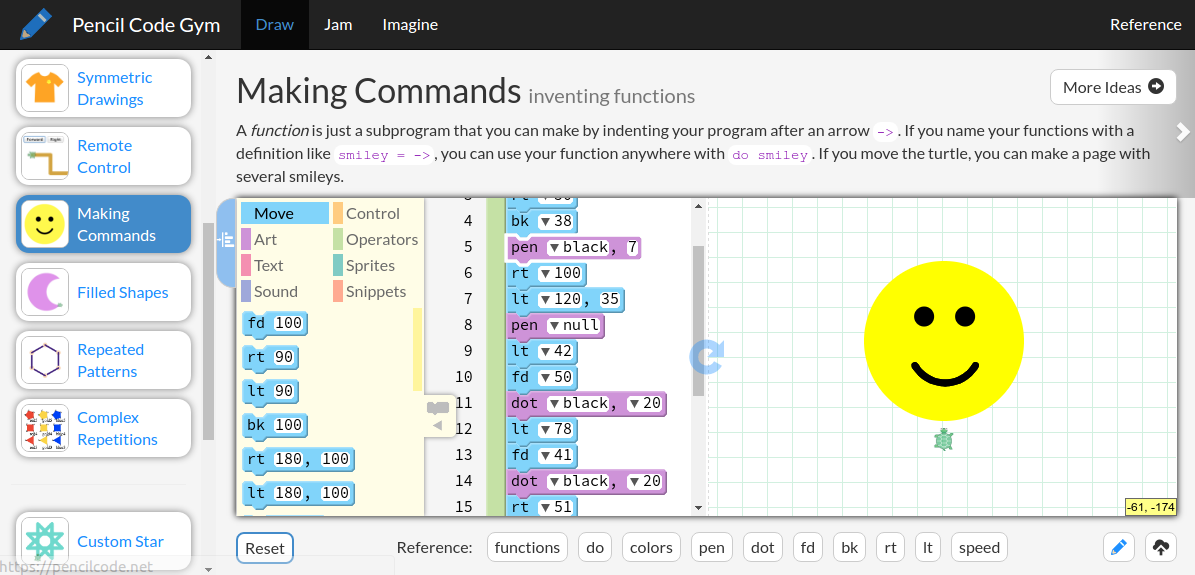 Pencil Code is an open-source
project that makes it easier for novice programmers to work with
professional programming languages.
Developed together with my son and with the generous
support of Google, this system provides a blocks-based editing environment
with turtle graphics on a canvas that smoothly transitions to text-based
editing of web applications using jQuery. Two thousand students use the
system each day. A study of middle-school
students using the environment suggests suggests the block-and-text
transitions are an aid to learning.
D Bau, D A Bau, M Dawson, C S Pickens. Pencil code: block code for a text world. In Proceedings of the 14th International Conference on Interaction Design and Children, pp. 445-448. ACM, 2015.
Pencil Code is an open-source
project that makes it easier for novice programmers to work with
professional programming languages.
Developed together with my son and with the generous
support of Google, this system provides a blocks-based editing environment
with turtle graphics on a canvas that smoothly transitions to text-based
editing of web applications using jQuery. Two thousand students use the
system each day. A study of middle-school
students using the environment suggests suggests the block-and-text
transitions are an aid to learning.
D Bau, D A Bau, M Dawson, C S Pickens. Pencil code: block code for a text world. In Proceedings of the 14th International Conference on Interaction Design and Children, pp. 445-448. ACM, 2015.
![]() Google Image Search is the world's largest searchable index of images.
I contributed several improvements to this product, including improved ranking for recent images, a clustered broswing interface for discovering images using related searches, a rollout of new serving infrastructure to support a long-scrolling result page
serving one thousand image results at a time, and improvements in the understanding of person entities on the web.
M Zhao, J Yagnik, H Adam, D Bau, Large scale learning and recognition of faces in web videos. In Automatic Face & Gesture Recognition, 2008. FG'08. 8th IEEE International Conference on (pp. 1-7). IEEE, September 2008.
Google Image Search is the world's largest searchable index of images.
I contributed several improvements to this product, including improved ranking for recent images, a clustered broswing interface for discovering images using related searches, a rollout of new serving infrastructure to support a long-scrolling result page
serving one thousand image results at a time, and improvements in the understanding of person entities on the web.
M Zhao, J Yagnik, H Adam, D Bau, Large scale learning and recognition of faces in web videos. In Automatic Face & Gesture Recognition, 2008. FG'08. 8th IEEE International Conference on (pp. 1-7). IEEE, September 2008.
 Google Talk
is a web-based chat solution that was built-in to GMail.
I led the team to create Google Talk in an (ultimately unsuccessful) attempt to establish a universal federated open realtime communication ecosystem for the internet. Our messaging platform provided full-scale support for XMPP and Jingle, which are open standards for federating real-time chat and voice that are analogous to the open-for-all SMTP system for email. When these open protocols came under asymmetric attack by Microsoft (they provided only one-way compatibility), Google relented and reverted to a closed network. To this day, open realtime communications remains an unfulfilled dream for the internet.
D Bau. Google Gets to Talking. Google Official Blog, August 2005.
Google Talk
is a web-based chat solution that was built-in to GMail.
I led the team to create Google Talk in an (ultimately unsuccessful) attempt to establish a universal federated open realtime communication ecosystem for the internet. Our messaging platform provided full-scale support for XMPP and Jingle, which are open standards for federating real-time chat and voice that are analogous to the open-for-all SMTP system for email. When these open protocols came under asymmetric attack by Microsoft (they provided only one-way compatibility), Google relented and reverted to a closed network. To this day, open realtime communications remains an unfulfilled dream for the internet.
D Bau. Google Gets to Talking. Google Official Blog, August 2005.
 Apache XML Beans is an open-source implementation of the XML Schema specification as a compiler from schema types to Java classes.
Still used as a powerful document interchange technology, my team's implementation of this standard is a good example of an important approach that continues to be a key technique for the creation of understandably complex systems: the prioritization of faithful and transparent data representations over simplified but opaque functional encapsulations.
D Bau. The Design of XML Beans, davidbau.com, a dabbler's weblog, November 2003.
Apache XML Beans is an open-source implementation of the XML Schema specification as a compiler from schema types to Java classes.
Still used as a powerful document interchange technology, my team's implementation of this standard is a good example of an important approach that continues to be a key technique for the creation of understandably complex systems: the prioritization of faithful and transparent data representations over simplified but opaque functional encapsulations.
D Bau. The Design of XML Beans, davidbau.com, a dabbler's weblog, November 2003.
 Microsoft Internet Explorer 4 was the first AJAX web browser.
As part of the Trident team led by Adam Bosworth, I helped create the first fully mutable HTML DOM by defining its asynchronous loading model. My contribution was to implement an incremental HTML parser that uses speculative lookahead to drive a fast multithreaded preloader for linked resources, while maintaining a consistent view of programmable elements for single-threaded scripts that can change the document during loading.
The design of the system resolved tensions between performance, flexiblity, and programmability, and contributed to the strength of the modern web platform.
Microsoft Internet Explorer 4 was the first AJAX web browser.
As part of the Trident team led by Adam Bosworth, I helped create the first fully mutable HTML DOM by defining its asynchronous loading model. My contribution was to implement an incremental HTML parser that uses speculative lookahead to drive a fast multithreaded preloader for linked resources, while maintaining a consistent view of programmable elements for single-threaded scripts that can change the document during loading.
The design of the system resolved tensions between performance, flexiblity, and programmability, and contributed to the strength of the modern web platform.
 Numerical Linear Algebra is the graduate textbook on numerical linear algebra I wrote with my advisor Nick Trefethen while earning a Masters at Cornell.
The book began as a detailed set of notes that I took while attending Nick's course. The writing is intended to capture the spirit of his teaching: succinct and insightful. The hope is to reveal the elegance of this family of fundamental algorithms and dispel the myth that finite-precision arithmetic means imprecise thinking.
L N Trefethen, D Bau. Numerical linear algebra. Vol. 50. Siam, 1997.
Numerical Linear Algebra is the graduate textbook on numerical linear algebra I wrote with my advisor Nick Trefethen while earning a Masters at Cornell.
The book began as a detailed set of notes that I took while attending Nick's course. The writing is intended to capture the spirit of his teaching: succinct and insightful. The hope is to reveal the elegance of this family of fundamental algorithms and dispel the myth that finite-precision arithmetic means imprecise thinking.
L N Trefethen, D Bau. Numerical linear algebra. Vol. 50. Siam, 1997.